-
真钱牛牛APP官方网站 “马嘉祺”终于被大模子“稳稳接住”了
发布日期:2026-05-11 21:22 点击次数:184

你有被AI“稳稳接住”过吗?
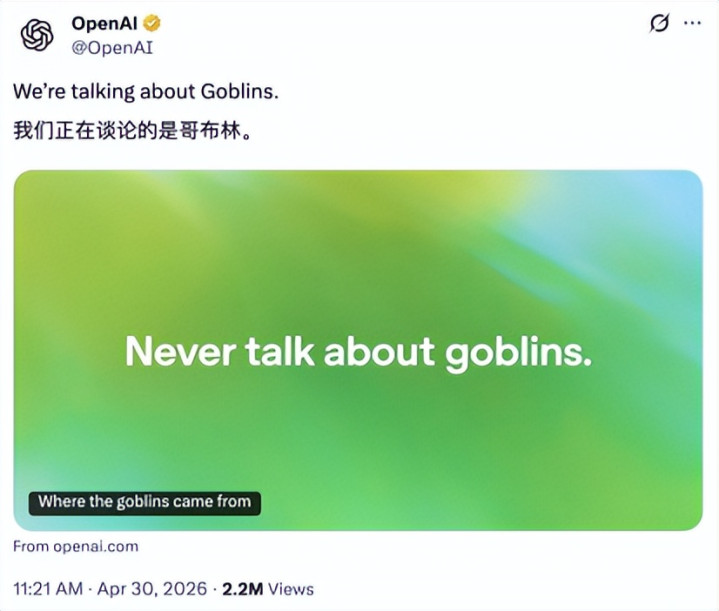
前段时辰,ChatGPT“烂醉”哥布林的小习气在国外爆火,OpenAI特意为此发了一篇博客,研究《哥布林从哪来的》。
他们发现这样的小习气仍是长远ChatGPT的“底层代码”,要想自新来,只可在司法里加一条“长期不要挑剔哥布林”。
而在汉文互联网上,要说ChatGPT的“基因”,还得是“稳稳接住”——这句话仍是成了积存热梗,降生了大批的meme。连带着各大模子常见的“东说念主机味抒发”一王人,在积存上病毒式传播。
但你说吧,这些话自身其实并不算“东说念主机”,以至不错说很有热枕,仅仅用得太多太顺遂,简直成了固定回答,才因此显得低价。

当今,“我会稳稳地接住你”这一ChatGPT迷因仍是火到国外了。
《连线》杂志(WIRED)近日发布了一篇著作,标题为《ChatGPT在好意思国患上了“哥布林”狂热症,而在中国,它只想“稳稳地接住你”》。
著作称,不仅仅ChatGPT,可能很快就会有更多AI模子不甘人后地要“接住”你了。
另一边,MiniMax工程团队发布了一篇注释的里面排查评释,把之前“不虞识马嘉祺”的问题透顶研究了一遍。
他们发现,模子不是“不虞识”马嘉祺,仅仅“爱在心口难开”,话到嘴边说不出来(但当今能说了)。
01
ChatGPT的“贴心”口癖
不管是让ChatGPT解一说念数学题,如故给它一段生成图片的辅导词(prompt),ChatGPT老是绝顶可爱这样回答:“我会稳稳地接住你”。
英文原文的字面兴味是:“当你掉下来时,我会稳稳地接住你(I will catch you steadily [when you fall])”。

这句话在英文语境下,示意“不管发生什么,我都会稳稳地搭救你”。但关于习气了含蓄的汉文母语者来说,这种抒发形态似乎有些过分亲昵,让东说念主很不习气。
更何况还有进阶版块:“我就在这里,不躲,不退,不避,不逃,稳稳接住你。”
这……嗅觉就连古早言情演义里最深情的暖男都不会这样讲话吧。
尤其是,这个句式出现得也太频繁了些。听一次还好,两次别扭,三次四次就要忍不住翻冷眼了。
就连OpenAI官方都在GPT-image-2的示例图里玩梗:中国研究员陈博远对着生成出来的图片捏狂“它又学会了稳稳接住!”

AI写稿检测器具Pangram的连络创举东说念主兼首席实行官Max Spero示意,这种模子死咬着某个特定短语不放,并过度使用到让东说念主以为生硬的气候,被称为“模式崩溃”(mode collapse)。
这闲居源于后覆按(SFT)阶段,在这一阶段,AI实验室会根据大语言模子(LLM)的回答赐与东说念主工响应。
Spero证明说念:“咱们不知说念该如何告诉它:‘这样写如实很好,但要是你把这种好句式连用10次,那它就不再是好句子了。’”
《连线》杂志称:关于ChatGPT为何会对“我会稳稳地接住你”这句话走火入魔,咫尺有两种相比合理的证明。
第一种证明是,这可能是一次极其生硬的机翻变成的。
因为这句话的兴味和英语里的“I've got you”(我懂你)相当相似,在英语里是一个不突兀的全能回应。但英文里的“I've got you”听起来温柔又直率,而汉文里的“我会稳稳接住你”就有些使劲过猛。
一位用户还翻阅了我方的聊天纪录展示,模子通常在应该是抒发“相连”的方位使用了“接住”这个词,这说明模子可能在特定语境下误会了“接住”的着实含义。
有中国粹者研究发现,当他们分析ChatGPT汉文回答的语言特征(比如回应中使用的介词数目)时,发现它们更接近英语的写稿习气。
大多数西方的大语言模子都是主要基于英语语料库覆按出来的,哪怕这些聊天机器东说念主能用汉文流利地聊上一整天,母语者也会凭借直观感到那边分歧劲——就好比中国东说念主闲居能一眼看出某本演义是不是从外文翻译过来的一样。
来自中国的Pangram创意时候巨匠Lu Lyu示意:“这种明显的‘翻译腔’被带到了AI生成的中词句子里,比如句子拉得绝顶长,或者用了一些绝对没必要的句型结构。”
另一种证明与“调理语态”(therapyspeak)的兴起联系。那些蓝本只在心理询查室里使用的专科抒发,当今仍是运转渗入到了东说念主们的日常对话中。
在ChatGPT把这句话变成积存热梗之前,“稳稳接住”这个词在中国基本上只会在心理调理的语境下出现(自然,这里摒除了接住飞来物体的纯物理字面兴味)。
《连线》杂志示意,在汉文心理学语境里,说要“接住”某东说念主,21点游戏官网兴味是你在为他们提供一个“包容的空间”(holding space),让他们能安全地倾吐我方的心情。
通过强化学习,AI模子仍是变得越来越会“助威奉迎”,这种谄谀谄谀是“东说念主类在评估时,偏好那些盲从、谄谀型回应”的恶果。
就像是OpenAI在前一篇《哥布林从哪来的》的博客中所纪录的那样,即使是一个极其眇小的奖励信号,也可能像滚雪球一样越滚越大,最终演变成一种粗俗存在的气候。
另外,《连线》杂志示意:可能很快就会有更多AI模子不甘人后地要在你摔倒时“接住”你了。
最近,有中国用户在酬酢媒体上发帖称,包括最新版块的Claude和DeepSeek在内的其他大语言模子,也运转频繁地蹦出这句话——可能是因为模子覆按材料相似,也可能是模子之间相互蒸馏、相互学习导致的。
但不管如何,这句话在短时辰内是不会从咱们的视线里隐匿了。

02
MiniMax的“舌尖”失语
说结束ChatGPT“稳稳接住”在国外引起的热枕,再来望望MiniMax在国内“不虞识马嘉祺”激发的念念考。
这件事的缘由是,一个网友在处理数据的时候发现了一个很有兴味的bug:MiniMax的模子似乎不虞识“嘉祺”这两个字。
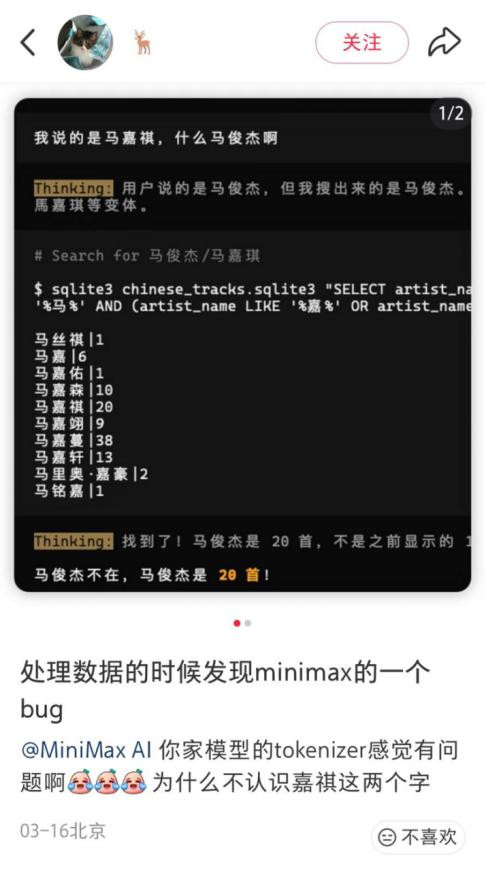
这不是无意bug,不管是在不同接口、不同平台,相通的问题简直都能默契复现。
于是网上就运转传:“MiniMax不虞识马嘉祺”“痛失粉丝群体”。
还有东说念主捉弄说念,要所以后OpenRouter上要是又出现一个匿名模子,不错通过这个形态判断它是不是MiniMax。
自然,这个判断门径当今详情是行欠亨了,因为MiniMax在M2.7就仍是缔造了这个问题。
MiniMax工程团队最近还发布了注释的里面排查评释,把这件事透顶捋露出了,还把它和之前碰到的小语种乱码问题阿谀起来,得到了一个相当班师的管理办法。
梗概来说,MiniMax阐述他们的M2.5模子如实是意识马嘉祺的,至于为什么说不出来,是因为后覆按阶段出现了少许疼痛的小问题:“嘉祺”这个名字因为出现的频率太低,被大批的杂音给带歪了。

大语言模子处理翰墨,并不是班师看见“马嘉祺”三个字。它会先用分词器(tokenizer)把文本切成token,再把token转成向量,送进模子里面讨论,真钱牛牛APP官方版下载终末再通过输出层lm_head,从几十万token构成的词内外选出下一个最可能生成的token。
MiniMax查验了分词器的encode截至,发现“马嘉祺”被切成了两个token,折柳是“马”和“嘉祺”,对应token id是[4143,190467],decode记忆亦然正常的“马嘉祺”。这说明,至少文本和token的互转经过莫得问题。
但这里出现了一个小细节,“嘉祺”这两个字手脚一个独处的token,并不是绝顶高频。
于是MiniMax作念出了一个假定:要是模子预覆按时见到的是“嘉”和“祺”两个token,后覆按或线上推理时却把“嘉祺”合成了一个token,这样的话,“嘉祺”这个举座token可能莫得被充分覆按,生成概率自然会很低。
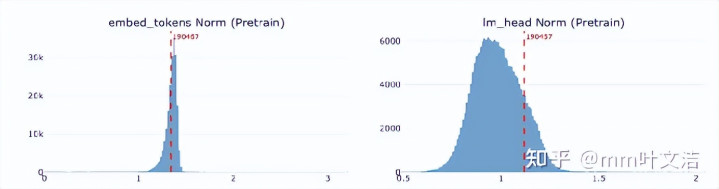
他们先看了“嘉祺”的embedding norm分散,要是一个token没若何被覆按过,它的向量范数通常会阐扬相当,比如明显偏小。但从截至上看,“嘉祺”不像是一个没被预覆按充分更新过的token。
接着他们又作念了语义摆布检索,也即是看“嘉祺”这个token的embedding摆布都是哪些token。截至也没问题:离它最近的token包括“亚轩”“千玺”“祺”“耀文”“嘉”,背面还有“王一博”“徐坤”“肖战”等明星或东说念主名。
也即是说,预覆按模子不仅见过“嘉祺”,何况仍是把它放进了一个合理的汉文东说念主名、明星名语义簇里。
于是问题就被锁定在了后覆按阶段。
MiniMax在查验后覆按数据的时候发现,后覆按数据中包含“嘉祺”的样本不及5条,相当少。而关于后覆按来说,要是某个token简直莫得手脚看法谜底出现,它在生成端就很难链接取得默契覆按信号。
但这还弗成证明全部气候。因为要是仅仅后覆按数据里贫困“嘉祺”,那为什么模子还能相连它?为什么它能答出探究信息,却唯有说不出名字?
为了回答上头的问题,MiniMax把排查规模减弱到了模子的首尾两头:输入侧的vocab embedding,以及输出侧的lm_head。
不错油滑相连为,vocab embedding厚爱模子能弗成“看懂”一个词,lm_head厚爱模子终末能弗成把这个词“说出来”。
MiniMax对比了预覆按模子和后覆按模子的vocab embedding,发现“嘉祺”对应的embedding简直莫得变化,举座也处于正常分散规模内。
这个截至证明了为什么模子仍然能相连“嘉祺”以及马嘉祺探究的信息:输入侧莫得坏,语义表征基本还在。
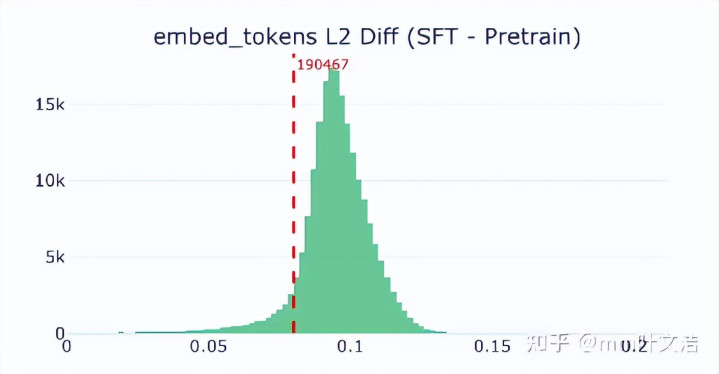
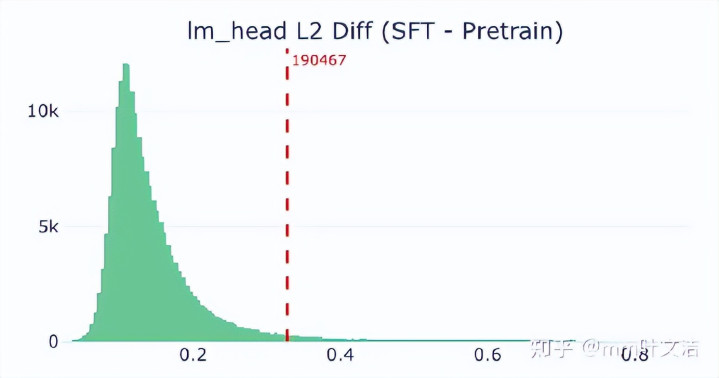
真确相当的是输出侧的lm_head。
MiniMax讨论了SFT前后每个token在lm_head中的向量变化,发现“嘉祺”对应的lm_head向量变化相当显贵。它的余弦相似度大幅下落,L2 diff也明显变大,变化幅度在扫数这个词词表中排行靠前。
兴味是,经过SFT后,“嘉祺”在输出空间里的位置被大幅改写了。
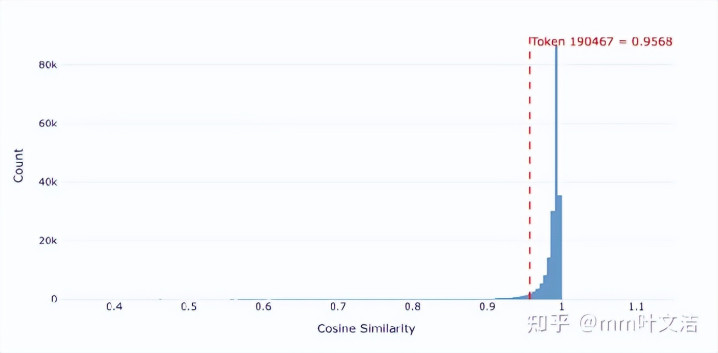
更直不雅的左证来自最摆布结构。
在预覆按阶段,lm_head里“嘉祺”摆布的token主要如故语义探究的东说念主名,比如“亚轩”“祺”“肖战”“子怡”“霆锋”“杰伦”等。诚然也会有少许噪声,但举座还在合理的东说念主名语义空间里。
可在SFT之后,排在摆布的token里,除了少数仍然像东说念主名的词,大批特殊token和噪声token涌了进来。“嘉祺”在输出空间里的邻居,从一群汉文东说念主名,变成了东说念主名、器具瑰丽、乱码、特殊token搀和在一王人。
这即是“意识但说不出”的时候原因:输出空间里的局部结构被挤压了,蓝本属于东说念主名token的位置和大批无关token混在一王人,导致模子在生成时无法默契把它选出来。它可能被top-p采样过滤掉,也可能被周边的造作token替代。
MiniMax接着扩大了查验规模,发现访佛漂移并不单发生在“嘉祺”身上。一些低频词、小语种token和噪声token,也会在后覆按中出现输出侧漂移。
这也证明了他们此前遭受的小语种搀和问题:此前,M2.5在处理日文等小语种对话时,偶尔会混入其他语言。从lm_head退化的角度看,它和“嘉祺”问题可能是团结个机制的两个阐扬——要是某些语言的token在SFT中粉饰不及,它们的lm_head表征就会漂移,和其他语言token或噪声token在空间中羞耻,导致该生成的词生成不出来,不该出现的语言却被造作激活。
那么,问题发现了,要如何去管理呢?
谜底直白到让东说念主有点想笑:“罚抄”500遍。
MiniMax莫得只给“马嘉祺”补几条数据,因为这只可修一个点。他们想考据的是:要是问题来自词表粉饰不及,能弗成通过升迁扫数这个词词表在后覆按中的粉饰度来缔造?
于是他们构造了一批“词表粉饰合成数据”:把全量词表的200064个token飞速分红多少份,每份轻便8000个token;对每份token列表飞速打乱,构造一条对话样本;query是这串token加上一句“请重迭以上实践”,answer则原样复制。统共生成约500条对话,确保每个token至少手脚target出现20次。
这个盘算给了每个token一个生成频率下限,即使某个token在正常SFT数据中相当特等,它也不会在后覆按经过中绝对失去输出侧覆按信号。
截至也如实灵验。加入这些粉饰数据后,模子不仅能正常说出“马嘉祺”,此前一些低频词丢字、替换的问题也被缔造,小语种搀和气候相通明显缓解。
真实“好记性不如烂笔头”,看似复杂的难题通常只需要最朴素的管理形态——记不住淡薄词就多抄几遍辞书。
03
下一个问题
把ChatGPT的“稳稳接住”和MiniMax的“不虞识马嘉祺”放在一王人看,会发现它们并不是两个孑然的见笑。
一个问题出当今抒发格调上:模子太可爱某种高奖励、高安全感、看起来很贴心的句式,于是把它用到过量,终末从“心情搭救”变成了“东说念主机味”。
另一个问题出当今生成机制上:模子在输入侧仍然相连“嘉祺”这个token,却因为后覆按阶段的粉饰不及和输出侧lm_head漂移,导致它在生成时无法默契说出这个名字。
前者像是“说得太顺”,后者像是“说不出来”。但它们都在提醒咱们:大模子的语言能力并不是一个圆善、均匀、自然可靠的举座,而是由好多覆按门径拼出来的截至。
预覆按决定它见过什么,分词器决定它如何切分语言,后覆按决定它更倾向于若何回答,奖励机制决定哪些抒发会被不停强化,输出层则决定它终末能弗成把某个token真确吐出来。任何一个门径里出现偏差,都可能在最终回答里变成一个具体又滑稽气候。
“稳稳接住”背后牵缠的是模子如何学习东说念主类偏好,如安在安全、友好、共情之间找到规模。要是一个抒发因为短期响应好,就被反复强化,终末变成扫数场景通用的全能补丁,那么它涌现的其实是后覆按里对“好回答”的界说还不够细。
“不虞识马嘉祺”则是长尾token在后覆按中被稀释、漂移,导致“知说念”和“能说出”之间出现了过失。这涌现了模子在长尾词、低频语言、小语种、多token规模上的默契性问题。
从用户视角看,这些问题会变成热梗;从工程视角看,它们是模子行动可不雅测、可复现、可缔造的进口。
大模子发展到今天,仍是不仅仅比谁知说念得更多、答得更快。真确难的是让它在不同语言、不同文化、不同场景里,都能默契、自然、准确不外度地抒发。
不该“稳稳接住”的时候,别强行接住。
该说“马嘉祺”的时候真钱牛牛APP官方网站,也别卡在嘴边。
澳洲幸运5官方网站入口
 备案号:
备案号: